

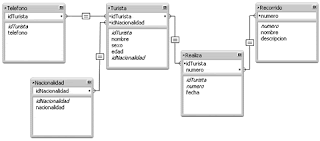
Sin embargo, antes de construir la base de datos en FileMaker, debemos considerar los casos de uso de la aplicación.
Los casos de uso describen que es lo que hará la aplicación y no tanto como lo hará, eso viene después, de momento necesitamos entender que haremos con la aplicación, como vamos a utilizar la aplicación y eso también nos dará una idea de las interfaces de usuario que deberemos diseñar, así como el esquema de operación de la misma.
¿Cuales son los casos de uso de la aplicación?

Catálogos.
Los primero tres casos de uso nos permitirán mantener los catálogos de la aplicación, estos catálogos serán: Nacionalidades, Turistas y Recorridos Turísticos.
Por lo tanto debemos diseñar una presentación, que permita la creación y modificación de registros para las tablas Nacionalidad, Recorrido y Turista, así como una presentanción quizas para listados en cada una de esas tablas.
En la presentación para el Alta de turistas se deberá incorporar un portal que permita la creación de registros relacionados hacia la tabla Teléfono.
Para la tabla Telefono, no es necesario crear una presentación, ya que la navegación en el sistema será desde la tabla Turista, así que podemos eliminar la presentación que el sistema crea por defecto para la tabla Telefono.
Dentro de la presentación de captura en la tabla Turista, adicionalmente a colocar un portal para los teléfonos, creamos una lista de valores para el campo idNacionalidad y a esa lista de valores, le asignamos el campo nacionalidad de la tabla Nacionalidad.
Para las tablas Nacionalidad, Turista y Recorridos, podemos crear presentaciones para captura, consulta y listados.
Funcionalidad de recorridos turísticos.
El último caso de uso lo hemos llamado: "Alta de Recorridos Realizados", esto es completamente distinto a lo que se refiere el caso de uso sobre Alta de Recorridos, este último es el manejo del catálogo de recorridos turísticos que ofrece la empresa y el primero se refiere a los recorridos que realiza un turista.
Estos recorridos realizados serán las visitas realizadas por los turistas dentro de los recorridos turísticos, razón por la cual se creo la tabla Realiza, que en realidad son las visitas llevadas a cabo en una fecha dada y hacia un recorrido determinado.
En esta tabla, "Realiza", se guardará un registro por cada turista que visita un mismo recorrido y en la misma fecha, es decir, Si el recorrido 1 es llevado a cabo por 20 turistas, entonces la tabla Realiza tendrá para este caso 20 registros, uno por cada turista, pero los 20 registros tendrán el mismo recorrido y la misma fecha. Si quisieramos mantener un catálogo de visitas o recorridos realizados, uno por cada recorrido en un fecha determinada, dentro del cual existen varios turistas, entonces debemos hacer un cambio en el diseño.
A estas alturas del diseño y una vez que empezamos a analizar los casos de uso, nos damos cuenta que nos hace falta considerar esta opción, por eso comentamos lineas arriba que aún no era prudente empezar a crear las tablas en FileMaker.
Realiza será una visita, por lo que se requiere descomponer la relación entre Realiza y Turista, la cual es una relación todavía de muchos a muchos, por lo tanto al realizar dicha descomposición creamos una tabla intermedia entre estas dos tablas que llamaremos Turista en Recorrido, a la cual pasamos el idTurista de la tabla Realiza y para lograr la integridad referencial adicionamos un idVisita en la tabla realiza que será autonuérico y que nos permitira establecer la relación con la tabla Turista en Recorrido quedando de la siguiente manera:

Como observamos en la figura, se creo una tabla adicional llamada Turista en Recorrido, la cual contiene dos campos: idVisita e idTurista, adicionalmente se modifcó la tabla Realiza eliminando el campo idTurista y agregando un campo llamado idVisita, el cual será autonumérico, para establecer la relación entre Realiza y Turista en Recorrido, de esta manera podremos colocar un portal en la presentación de Realiza para mostrar los registros relacionados de la tabla Turista en Recorrido, esta relación deberá permitir crear y borrar registros relacionados en la tabla Turista en Recorrido.
Ahora si tenemos el diseño final de la base de datos, por que para crear las tablas en FileMaker solo tenemos que establecer las consideraciones finales para los campos.
El siguiente punto es tomar en cuenta las consideraciones para cada uno de los campos en totas las tablas, así como la creación de las relaciones entre tablas.


Una vez creadas las tablas (Nacionalidad, Telefono, Turista, Recorrido, Realiza y Turista en Recorrido) con estas consideraciones en los campos, establecemos las relaciones entre ellas.
Parra ello, arrastramos desde la tabla Telefono, en esta relación se activarán las casillas para crear registros relacionados y eliminar registros relacionados en la tabla Telefono desde la tabla Turista, para la siguiente relación arrastramos el campo idTurista hacia el campo idTurista en la tabla Turista, el campo idNacionalidad desde la tabla Turista hacia el campo idNacionalidad en la tabla Nacionalidad.
El campo idTurista desde la tabla Realiza hacia el campo idTurista en la tabla Turista en Recorrido, esta relación debe permitir el borrado y la creación de registros relacionados en la tabla Turista en Recorrido desde la tabla Realiza, adicionalmente arrastramos el campo numero desde la tabla Realiza hacia el campo numero en la tabla Recorrido.
Por último arrastramos el campo idTurista de la tabla Turista en Recorrido hacia el campo idTurista en la tabla Turista.
Los valores de los campos idTurista en la tabla turista, así como número en la tabla Recorrido y el campo idNacionalidad de la tabla Nacionalidad serán asignados automáticamente por el sistema.
Finalmente, para dar de alta a los turistas que realizan recorridos, creamos una presentación para la tabla Realiza, en ella establecemos una lista de valores para el campo numero en el que asignamos el campo numerode la tabla Recorrido, de esta forma podemos escoger el recorrido turístico y mostrar en la presentación su nombre, para ello no se requiere un portal, simplemente colocar los campos relacionados de la tabla Recorrido en la presentación de la tabla Realiza.
Posteriormente colocamos un portal con los registro relacionados de la tabla Turista en Recorrido, aunque en este portal colocamos los campos de la tabla Turista.
Adicionalmente, si deseamos visualizar que recorridos ha hecho un turista, entonces, en la presentación de consulta para la tabla Turista podemos colocar un portal asigando a la tabla Realiza, pero en el colocamos campos de la tabla Recorrido, de esa forma podemos tener un historia de los recorridos que ha realizado un turista.
El archivo con el ejemplo que desarrollamos en estos cuatro artículos lo pueden descargar para su revisión en la siguiente dirección:
Turista.fp7

 Para cada persona tenemos varios números telefónicos.
Para cada persona tenemos varios números telefónicos. La primera forma normal es una restricción inherente al modelo relacional, por lo que su cumplimiento es obligatorio para todas las tablas.
La primera forma normal es una restricción inherente al modelo relacional, por lo que su cumplimiento es obligatorio para todas las tablas. Algunos turistas turistas tienen uno, dos o tres números, no todos tienen los tres números para los cuales tenemos capacidad en la tabla.
Algunos turistas turistas tienen uno, dos o tres números, no todos tienen los tres números para los cuales tenemos capacidad en la tabla.


 La fecha no la colocamos en el recorrido, ya que la entidad Recorrido es un catálogos de los recorridos turísticos que se ofrecen y que se realizan en distintas fechas por distintos turistas, así que la fecha la colocamos en la relación entre ambas entidades.
La fecha no la colocamos en el recorrido, ya que la entidad Recorrido es un catálogos de los recorridos turísticos que se ofrecen y que se realizan en distintas fechas por distintos turistas, así que la fecha la colocamos en la relación entre ambas entidades. Como se mencionó anteriormente y podemos observar en la figura de la tablas, la tabla Turista contiene un atributo adicional (campo) llamado idTurista, el cual se convierte en la clave primaria de esta tabla, es el atributo que nos permite establecer un identificador único para cada turista. Para el caso de la tabla Recorrido, el identificador único (clave primaria) será el número del recorrido.
Como se mencionó anteriormente y podemos observar en la figura de la tablas, la tabla Turista contiene un atributo adicional (campo) llamado idTurista, el cual se convierte en la clave primaria de esta tabla, es el atributo que nos permite establecer un identificador único para cada turista. Para el caso de la tabla Recorrido, el identificador único (clave primaria) será el número del recorrido.


